210824 화
1. 시퀀스
: 자동 번호 발생기 역할을 하는 객체
-순차적으로 정수 값을 자동으로 생성해줌
-UNIQUE한 값을 컬럼에 입력할 수 있음 / 일반적으로 PRIMARY KEY 값을 생성하기 위해 사용
1) SEQUENCE 생성
CREATE SEQUENCE 시퀀스 이름
[START WITH 숫자] -- 처음 발생시킬 시작 값 지정, 생략하면 자동 1 기본
[INCREMENT BY 숫자] -- 다음 값에 대한 증가치, 생략하면 자동 1 기본
[MAXVALUE 숫자 | NOMAXVALUE] -- 발생시킬 최대 값 지정
[MINVALUE 숫자 | NOMINVALUE] -- 발생시킬 최소 값 지정
[CYCLE | NOCYCLE] -- 값 순환 여부 지정
[CACHE 바이트 크기 | NOCACHE] -- 캐쉬 메모리 지정, 기본 값은 20바이트
CREATE SEQUENCE SEQ_EMP_ID
START WITH 300
INCREMENT BY 5
MAXVALUE 310
NOCYCLE
NOCACHE;--유저가 생성한 시퀀스 데이터 딕셔너리에서 확인
SELECT * FROM USER_SEQUENCES;
2) SEQUENCE 사용
시퀀스명.CURRVAL : 현재 생선된 시퀀스 값
시퀀스명.NEXTVAL : 시퀀스 값을 증가 시킴. 기본 시퀀스 값에서 증가치만큼 증가한 값.
2-1) 오류 발생
SELECT SEQ_EMP_ID.CURRVAL FROM DUAL;
--sequence CURRVAL has been selected before sequence NEXTVAL
--오류 발생
--시퀀스는 NEXTVAL를 실행해야 CURRVAL를 실행할 수 있음
--CURRVAL는 마지막으로 호출된 NEXTVAL의 값을 저장하여 보여주는 임시 값이기 때문SELECT SEQ_EMP_ID.NEXTVAL FROM DUAL; --300
SELECT SEQ_EMP_ID.CURRVAL FROM DUAL; --300
SELECT SEQ_EMP_ID.NEXTVAL FROM DUAL; --305
SELECT SEQ_EMP_ID.CURRVAL FROM DUAL; --305SELECT SEQ_EMP_ID.NEXTVAL FROM DUAL;
--sequence SEQ_EMP_ID.NEXTVAL exceeds MAXVALUE and cannot be instantiated
--지정한 MAXVALUE 값을 초과했다는 오류 발생
SELECT SEQ_EMP_ID.CURRVAL FROM DUAL; --310
--310, CURRVAL는 성공적으로 호출된 마지막 NEXTVAL의 값을 저장하고 출력
3) CURRVAL / NEXTVAL 사용 가능 여부
(1) 사용 가능
1> 서브쿼리가 아닌 SELECT문
2> NSERT문의 SELECT절
3> INSERT문의 VALUES절
4> UPDATE문의 SET절
(2) 사용 불가
1> VIEW의 SELECT절
2> DISTINCT 키워드가 있는 SELECT문
3> GROUP BY, HAVING, ORDER BY절의 SELECT문
4> SELECT, DELETE, UPDATE문의 서브쿼리
5> CREATE TABLE, ALTER TABLE 명령의 DEFAULT값
CREATE SEQUENCE SEQ_EID
START WITH 300
INCREMENT BY 1
MAXVALUE 10000
NOCYCLE
NOCACHE;COMMIT;
3-1) 사용 가능 예시(INSERT문의 VALUES절 - PK용도)
INSERT INTO EMPLOYEE
VALUES (SEQ_EID.NEXTVAL, '김영희', '610410-2111111', 'young_123@kh.or.kr',
'01012331111', 'D1', 'J1', 'S1', 5000000, 0.2, 200, SYSDATE, NULL, DEFAULT);
INSERT INTO EMPLOYEE
VALUES (SEQ_EID.NEXTVAL, '김철수', '610410-1111111', 'cheol_123@kh.or.kr',
'01012321111', 'D1', 'J1', 'S1', 5000000, 0.2, 200, SYSDATE, NULL, DEFAULT);SELECT * FROM EMPLOYEE;
ROLLBACK;
3-2) 사용 불가 예시(CREATE TABLE, ALTER TABLE 명령의 DEFAULT 값)
CREATE TABLE EMP_EMPLOYEE(
E_ID NUMBER DEFAULT SEQ_EID.CURRVAL,
E_NAME VARCAHR2(30)
);
--column not allowed here 오류 발생
4) SEQUENCE 변경
ALTER SEQUENCE 시퀀스 이름
[INCREMENT BY 숫자]
[MAXVALUE 숫자 | NOMAXVALUE]
[CYCLE | NOCYCLE]
[CACHE 바이트 크기 | NOCACHE]
START WITH은 변경 불가(DROP 후 재생성)
ALTER SEQUENCE SEQ_EMP_ID
INCREMENT BY 10
MAXVALUE 400
NOCYCLE
NOCACHE;--시퀀스 변경 확인
SELECT * FROM USER_SEQUENCES;
SELECT SEQ_EMP_ID.NEXTVAL FROM DUAL; --320
SELECT SEQ_EMP_ID.CURRVAL FROM DUAL; --320
5) SEQUENCE 삭제
DROP SEQUENCE SEQ_EMP_ID;SELECT * FROM USER_SEQUENCES;2. DCL(DATA CONTROL LANAGUAGE) : 데이터 제어어
: 데이터 베이스, 데이터 베이스 객체에 대한 접근 구너한을 제어(부여, 회수)하는 언어
-GRANT(부여), REVOKE(회수)
1) 계정 종류
(1) 관리자 계정
: 데이터 베이스의 생성과 관리를 담당하는 슈퍼 유저(Super User) 계정
-오브젝트의 생성, 변경, 삭제 등의 작업이 가능
-데이터 베이스에 대한 모든 권한과 책임을 가지는 계정
(2) 사용자 계정
: 데이터 베이스에 대해 질의, 갱신 등의 작업을 수행할 수 있는 계정
-일반 계정은 보안을 위하여 업무에 필요한 최소한의 권한만 가지는 것이 원칙
2) 권한
(1) 시스템 권한 : 사용자에게 시스템 권한을 부여하는 권한
-CREATE SESSION : 데이터 베이스 접속할 수 있는 권한(계정 접속)
-CREATE TABLE : 테이블 생성 권한
-CREATE VIEW : 뷰 생성 권한
-CREATE SEQUENCE : 시퀀스 생성 권한
1> 표기법
GRANT 권한1, 권한2, ... TO 사용자 이름;
2> 실습
<1> SYS 계정으로 SAMPLE 계정 생성하기
CREATE USER sample IDENTIFIED BY sample;
--user SAMPLE lacks CREATE SESSION privilge
--권한이 없다고 오류 생김<2> 해당 계정에 접속하기 위해서 CREATE SESSION 권한 부여
GRANT CREATE SESSION TO sample;
<3> sample 계정으로 테이블 생성
CREATE TABLE TEST(
TID NUMBER PRIMARY KEY
);
--여기서부터 다시 듣기 3교시 20분 쯤
GRANT CREATE TABLE TO sample;
--.3_2. 해결하기 위해 테이블 스테이스 할당(sys로 실행)
ALTER USER sample QUOTA 2M ON SYSTEM;
(2) 객체 권한 : 특정 객체들을 조작할 수 있는 권한
1> 권한 종류 설정 객체
SELECT TABLE, VIEW, SEQUENCE
INSERT TABLE, VIEW
UPDATE TABLE, VIEW
DELETE TABLE, VIEW
ALTER TABLE, BIEW
...
2> 표기법
GRANT 권한 종류 [컬럼명]
ON 객체명 | ROLE 이름
TO 사용자 이름
3> 실습
<1> sample 계정에서 kh계정이 가지고 있는 EMPLOYEE 테이블에 접근
SELECT * FROM kh.EMPLOYEE;
--"table or view does not exist" 오류 발생
<2> sys 계정으로 sample 계정에게 kh.EMPLOYEE 테이블에 SELECT 권한 부여
GRANT SELECT ON kh.EMPLOYEE TO sample;
SELECT * FROM kh.EMPLOYEE;
--지금은 조회 가능!
--권한을 받은 후에 조회해야 함.
<3> sample 계정에서 kh 계정이 가지고 있는 DEPARTMENT 테이블에 데이터 삽입
INSERT INTO kh.DEPARTMENT VALUES('D0', '해외영업4부', 'L1');
--table or view does not exist 오류 실행
<4> SYS 계정으로 sample 계정에게 kh.DEPARTMENT 테이블 INSERT 권한 부여
GRANT INSERT ON kh.DEPARTMENT TO sample;<5> 권한 회수
REVOKE SELECT ON kh.EMPLOYEE FROM sample;
<6> 처음 계정 생성 후 사용자 계정에 RESOURCE, CONNET 권한을 부여했었음
--하나하나 권한을 부여하기 어려우므로 그룹으로 만들어서 부여(설치 시 기본 제공)
SELECT *
FROM DBA_SYS_PRIVS
--WHERE GRANTEE = 'CONNECT'
WHERE GRANTEE = 'RESOURCE';
(3) ROLE : 사용자에게 허가할 수 있는 권한들의 집합
1> ROLE : 생성
CREATE ROLE MYROLE2;2> ROLE에게 권한 부여
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW TO MYROLE2;3> ROLE을 사용자에게 부여
CREATE USER USER2 IDENTIFIED BY USER2;
GRANT MYROLE2 TO USER2;SELECT *
FROM DBA_ROLE_PRIVS
WHERE GRANTEE = 'USER2';SELECT *
FROM DBA_SYS_PRIVS
WHERE GRANTEE = 'MYROLE2';
--여기 다시 보기3. TCL(Transaction Control Language)
: 트랙잭션 관리 처리(제어) 언어
1) 용어
(1) COMMIT(트랜잭션 종료 처리 후 저장)
(2) ROLLBACK(트랜잭션 취소)
(3) SAVEPOINT(임시저장)
2) 트랜잭션
-데이터베이스의 논리적 연산 단위-
-데이터의 변경 사항들을 묶어서 하나의 트랜잭션에 담아서 처리
-트랜잭션의 대상이 되는 SQL : INSERT, UPDATE, DELETE(DML)
3) 실습
(1) 조회
SELECT * FROM EMP_01;
(2) EMP_ID가 900인 직원 삭제
DELETE FROM EMP_01
WHERE EMP_ID = 900;
SELECT * FROM EMP_01;--한 행 삭제 복구됨
ROLLBACK;
(3) 한 행이 삭제 된 상태에서 SAVEPONT 지정하기
DELETE FROM EMP_01
WHERE EMP_ID = 900;SELECT * FROM EMP_01;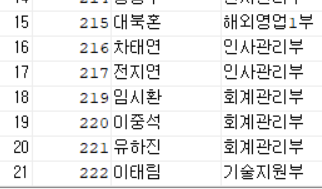
SAVEPOINT SP1;--SAVEPOINT 지정 후 한 행 더 삭제
DELETE FROM EMP_01
WHERE EMP_ID = 217;SELECT * FROM EMP_01;
--SAVEPOINT로 ROLLBACK
ROLLBACK TO SP1;--1명 삭제 되었던 SAVEPOINT 시점으로 ROLLBACK됨
SELECT * FROM EMP_01;
--마지막 COMMIT 시점으로 ROLLBACK
ROLLBACK;--처음 삭제 되었던 사원 복구
SELECT * FROM EMP_01;
4. INDEX
1) 정의
-인덱스는 어떤 종류의 검색 연산을 최적화하기 위해 데이터 베이스 상의 로우들의
정보를 구성하는 데이터 구조
-인덱스를 사용하면 전체 데이터를 검색하지 않고 데이터 베이스에서 원하는 정보를
빠르게 검색할 수 있음
2) 장단점
(1) 장점
-트리 형식으로 구성되어 자동 정렬 및 검색 속도가 빨라짐
-시스템에 걸리는 부하를 줄여 시스템 전체 성능 향상
(2) 단점
-인덱스를 추가하기 위한 별도의 저장 공간 필요
-인덱스를 생성하는데 시간이 걸림
-데이터 변경작업(DML)이 빈번한 경우에는 오히려 성능 저하
3) 인덱스를 관리하는 데이터 딕셔너리 조회
SELECT *
FROM USER_IND_COLUMNS;
--CREATE INDEX를 수행한 적 없지만 KH계정에 이미 인덱스 객체들이 많이 있음
--PK또는 UNIQUE 제약 조건이 걸린 컬럼을 대상으로 자동 인덱스 객체가 생성됨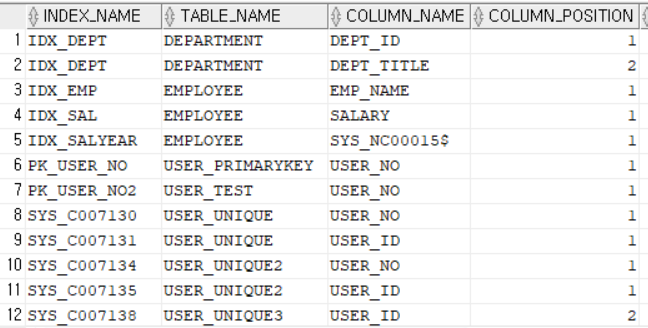
4) 인덱스 구조
*ROWID
: DB내 공유 데이터 공유 주소, ROWID를 이용해 데이터 접근 가능
(1) 번호별 의미
1~6 : 데이터 오브젝트 번호
7~9 : 파일 번호
10~15 : 블럭 번호
16~18 : 로우 번호
SELECT ROWID, EMP_ID, EMP_NAME
FROM EMPLOYEE;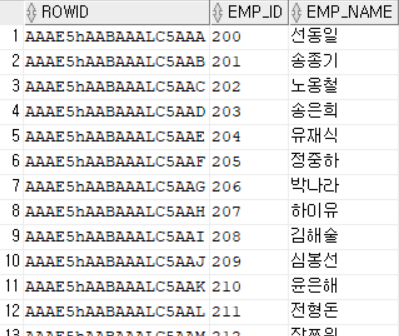
(2) 장점
-인덱스 생성시 지정한 컬럼은 KEY, ROWID는 VALUE가 되어 MAP처럼 구성
-SELECT시 WHERE절에 인덱스가 생성되어 있는 컬럼을 추가하면 데이터 조회시 테이블의 모든 데이터에 접근하는 것이 아닌 해당 컬럼(KEY)과 매칭되는 ROWID(VALUE)가 가리키는 ROW 주소의 값을 조회해줘 속도가 향상된다
5) 실습
(1) 인덱스를 활용하지 않은 SELECT문
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME = '윤은해';(2) 인덱스 활용한 SELECT문
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_ID = '210';
--> 인덱스를 사용했는지 확인하고 싶으면 계획설명을 눌러보아라
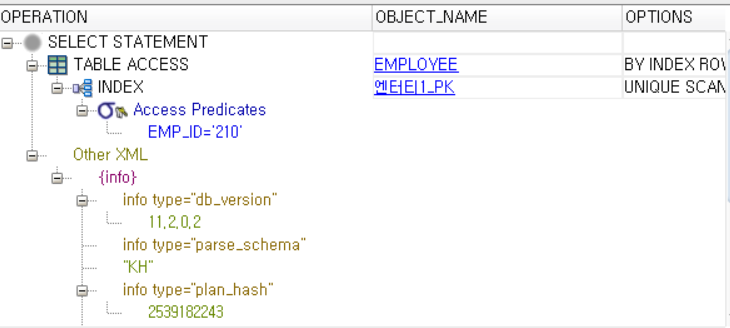
*WHERE절에 INDEX가 부여되지 않은 컬럼으로 조회시 윤은해가 어느 곳에 있는지 모르기 때문에 EMPLOYEE테이블 데이터 전부를 DB BUFFER 캐시로 복사한 뒤 FULL SCAN으로 찾게 됨(테이블 전체를 확인한다는 뜻)
*WHERE절에 INDEX가 부여된 컬럼으로 조회시 INDEX에 먼저 가서 210 정보가 어떤 ROWID를 가지고 있는지 확인한 뒤
해당 ROWID에 있는 블럭만 찾아가서 DB DUFFER 캐시에 복사
5) 인덱스 생성 방법
[표현식]
CREATE [UNIQUE] INDEX 인덱스명
ON 테이블명(컬럼명, 컬러명, ... | 함수명, 함수계산식);
(1) 고유 인덱스(UNIQUE INDEX)
-UNIQUE => 중복값이 없다
UNIQUE INDEX에 생성된 컬럼에는 중복값 포함 불가(== UNIQUE 제약 조건)
-오라클 PRIMARY KEY, UNIQUE 제약 조건 설정 시
해당 컬럼에 대한 INDEX가 존재하지 않으면 자동으로 해당 컬럼에 UNIQUE INDEX 생성함
1> EMPLOYEE 테이블의 EMP_NAME 컬럼에 UNIQUE INDEX 생성하기
CREATE UNIQUE INDEX IDX_EMP
ON EMPLOYEE(EMP_NAME);
2> 사용자가 생성한 인덱스 조회
SELECT *
FROM USER_INDEXES
WHERE TABLE_NAME = 'EMPLOYEE';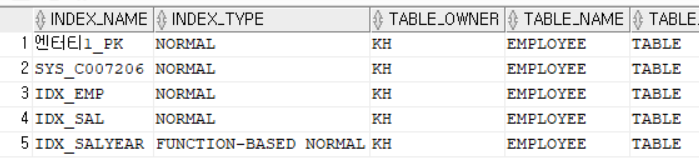
3> 인덱스의 키가 되는 컬럼 조회
SELECT *
FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'EMPLOYEE';
*PK(EMP_ID), UNIQUE(EMP_NO)에 대한 인덱스는 이미 자동생성되어 있으며 새로 생성한 IDX_EMP 인덱스가 추가 되어 있음. 이제 EMP_NAME에 중복된 값은 INSERT 불가능해짐
INSERT INTO EMPLOYEE
VALUES(100, '하이유', '111111-2222222', ' hi@kh.or.kr', '01011112222', 'D1',
'J7', 'S3', 3000000, 0.3, 201, SYSDATE, NULL, DEFAULT);
--unique constrait (KH.INX_EMP) violated
--원래 이름에 대한 UNIQUE 조건이 없었지만 UNIQUE 인덱스 생성으로 UNIQUE 값만 입력 가능
4> 컬럼 값들 중 중복 되는 값이 있을 경우 UNIQUE INDEX 생성 불가
CREATE UNIQUE INDEX INX_DEPTCODE
ON EMPLOYEE(DEPT_CODE);
--cannot CREATE UNIQUE INDEX; duplicate keys found
--오류 발생
(2) 비고유 인덱스(NONUNIQUE INDEX)
-빈번하게 사용되는 일반 컬럼을 대상으로 생성
-주로 성능 향상을 목적으로 생성
(3) 단일 인덱스(SINGLE INDEX)
-한 개의 컬럼으로 구성된 인덱스
CREATE INDEX IDS_DEPTCODE
ON EMPLOYEE(DEPT_CODE);--> 비고유(중복 값 포함 가능)이면서 단일(컬럼에 한개) 인덱스
1> 인덱스 이름 수정
ALTER INDEX IDS_DEPTCODE
RENAME TO IDX_DEPTCODE;
2> 인덱스 생성 여부 조회
SELECT *
FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'EMPLOYEE';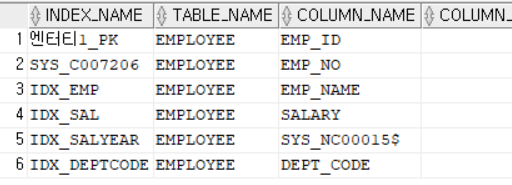
3> 인덱스 삭제
DROP INDEX IDX_DEPTCODE;
(4) 결합 인덱스(COMPOSITE INDEX)
: 두 개 이상의 컬럼으로 구성된 인덱스
1> DEPARTMENT 테이블의 DEPT_ID, DEPT_TITLE 결합 인덱스 생성
CREATE INDEX IDX_DEPT
ON DEPARTMENT(DEPT_ID, DEPT_TITLE);
2> 인덱스 생성 여부 조회
SELECT *
FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'DEPARTMENT';
--IDX_DEPT라는 하나의 인덱스 이름으로 두 컬럼이 생성됨
SELECT *
FROM DEPARTMENT
WHERE DEPT_ID = 'D4'
AND DEPT_TITLE = '국내영업부';
--IDX_DEPT라는 결합 인덱스 동작하지 않음
SELECT *
FROM DEPARTMENT
WHERE (DEPT_ID, DEPT_TITLE) = (SELECT DEPT_ID, DEPT_TITLE
FROM DEPARTMENT
WHERE DEPT_ID = 'D1');
--여기 값 안나옴 값 추가해야함
--조건에서 함께 사용해야 IDX_DEPT 결합 인덱스 동작
(5) 함수 기반 인덱스(FUNCTION-BAED INDEX)
-SELECT절이나 WHERE절에 산술 계산식이나 함수식이 사용된 경우 계산식은 인덱스의 적용을 받지 않음
-계산식으로 검색하는 경우가 많으면 수식이나 함수식을 인덱스로 만들 수 있음
1> SALARY 컬럼에 인덱스 생성
CREATE INDEX IDX_SAL
ON EMPLOYEE(SALARY);
2> 산술 계산식 함수식 사용하여 SELECT
SELECT EMP_ID, EMP_NAME, SALARY, ((SALARY + (SALARY * NVL (BONUS, 0))) * 12)
FROM EMPLOYEE
WHERE ((SALARY + (SALARY * NVL(BONUS,0))) * 12) > 30000000;
--SALARY 컬럼에 대한 인덱스는 있지만 계산식/함수식에 대한 인덱스는 없어 FULL SCAN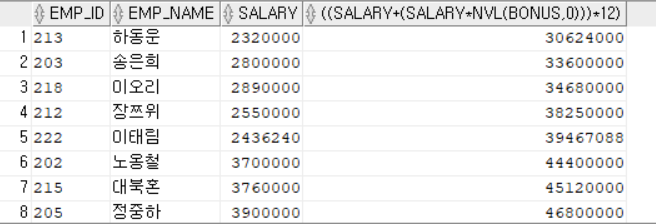
3> 함수 기반 인덱스 생성
CREATE INDEX IDX_SALYEAR
ON EMPLOYEE(((SALARY + (SALARY * NVL (BONUS, 0))) * 12));4> 산술 계산식 함수식 사용하여 SELECT
SELECT EMP_ID, EMP_NAME, SALARY, ((SALARY + (SALARY * NVL (BONUS, 0))) * 12)
FROM EMPLOYEE
WHERE ((SALARY + (SALARY * NVL(BONUS,0))) * 12) > 30000000;
--IDX_SALYEAR 인덱스 통한 검색
(6) 인덱스 재구성(INDEX REBUILD)
-DML 작업 명령을 수행한 경우 해당 인덱스 내에서 엔트리가 논리적으로만 제거 되고 실제 인트리는 그냥 남아있게 된다. 인덱스가 필요 없는 공간을 차지하고 있기 때문에 인덱스를 재생성할 필요가 있음
ALTER INDEX IDX_SAL REBUILD;
*INDEX는 데이터가 적어도 5만개 이상 정도의 데이터에서 그나마 효율적. 적은 데이터의 양에서는 오히려 비효율적임
DML을 많이 실행하지 않는 조회 목적의 테이블에서는 효율적이지만 DML을 실행하면 다시 인덱스를 조정하는데 시간이 걸려서 비효율적일 수 있음.
'웹개발 수업 > SQL' 카테고리의 다른 글
| [Day +45 / SQL]SYNONYM, PL_SQL (0) | 2021.08.25 |
|---|---|
| [Day +44 / SQL 과제]9문제 (0) | 2021.08.25 |
| [Day +43 / SQL]SQL 2차 시험 (0) | 2021.08.24 |
| [Day +42 / SQL 과제]DDL 15문제, DML 8문제 (0) | 2021.08.20 |
| [Day +42]DDL, VIEW (0) | 2021.08.20 |
